

公司地址:江西省南昌市
客服QQ:123456789
传 真:400-123-4567
英雄联盟 yingxionglianmeng 分类>>
否LoL赛事- LoL投注- 2025年最佳英雄联盟投注网站定AI眼镜传闻字节意在押注AI终端完整生态
 2026-01-08 10:15:05
2026-01-08 10:15:05 浏览次数: 次
浏览次数: 次 返回列表
返回列表英雄联盟投注,英雄联盟,英雄联盟下注,LOL投注官网,英雄联盟赛事投注,英雄联盟下注,英雄联盟电竞,英雄联盟投注网站,LOL,英雄联盟赛事,LOL投注,LOL赛事下注,LOL投注网站,lol下注平台虽然人工智能系统本身也有能力给出解释(如决策树、支持向量机等),但这些解释并不一定易于理解。例如,如果让人工智能解释“预测”(prediction)这个词,它可能会说:“参与预测的神经元由于前几层中n个神经元的一连串激活而被触发”。对于大多数人来说,这并不是一个易于理解的解释。类似的,在预测模型中人工智能喜欢用准确率、f-score、Cohen-kappa等测量方法来解释某种算法的性能,但它们并不能解释为什么此算法会达到这样的性能。
可解释人工智能的作用不仅仅是提供对模型预测的理解,还能揭示与大脑反应动态相关的深层神经机制。在诊断和康复的应用中,脑机接口的性能解释对于验证模型预测的正确性至关重要,而可解释人工智能提供了强有力的手段来实现这一点。有学者使用可解释人工智能从脑磁图(MEG)数据[7],成功识别出在伸手运动过程中处理运动参数(即加速度、速度和位置)的大脑皮层。除侵入性单神经元研究或大规模相干性研究外,可解释人工智能还提供了新的途径来研究大脑的运作机制。
目前的可解释人工智能技术也存在缺陷。有学者根据其意图将其分为两种:黑暗模式和陷阱模式[8-9]。“黑暗模式”旨在人工智能通过操纵对脑机接口的解释来伤害用户,而“陷阱模式”则是因一些知识盲区而导致人工智能产生了副作用。例如,有学者讨论了脑机接口研究中关于解码模型可解释性的一个常见误区[10]。他们强调,虽然解码模型旨在预测大脑状态以控制脑机接口,但往往存在一个隐性的假设,即这些模型的参数可以很容易地从大脑特性的角度进行人为解释。
人类普遍倾向于过度信任从有限数据集中得出的特定解释。但过度、盲目的信任存在巨大风险。因此,我们需要在设计和实施脑机接口系统时采取措施,防止利益相关者在决策中引入偏见。这意味着设计空间需要进一步发展,解释界面必须突出这一警示,提醒用户注意这些解释的潜在局限性和风险。例如,即便大脑的空间地图显示了模型预测的权衡位置,也不能保证这些大脑区域就是进行预测的最佳区域。这最终需要由利益相关者来识别和判断,以避免可能的错误。


虽然人工智能系统本身也有能力给出解释(如决策树、支持向量机等),但这些解释并不一定易于理解。例如,如果让人工智能解释“预测”(prediction)这个词,它可能会说:“参与预测的神经元由于前几层中n个神经元的一连串激活而被触发”。对于大多数人来说,这并不是一个易于理解的解释。类似的,在预测模型中人工智能喜欢用准确率、f-score、Cohen-kappa等测量方法来解释某种算法的性能,但它们并不能解释为什么此算法会达到这样的性能。
上文中,我们讨论了这些用于脑机接口的基元:脑机接口的驱动力(“为什么”)、利益相关者(“谁”)、应用领域(“是什么”)、界面(“如何做”)。结合这些元素,就可以构建一个全面的、以人为中心的XAI4BCI设计空间,以适mrqla7.cn/h0qla7.cn/ksqla7.cn/srqla7.cn/jhqla7.cn/esqla7.cn/g8qla7.cn/o8qla7.cn/k9qla7.cn/ch应和促进“人在回路”的脑机接口,进而实现下一步技术飞跃。图6利用图*(chord diagram)帮助我们直观地了解XAI4BCI的设计空间变量。
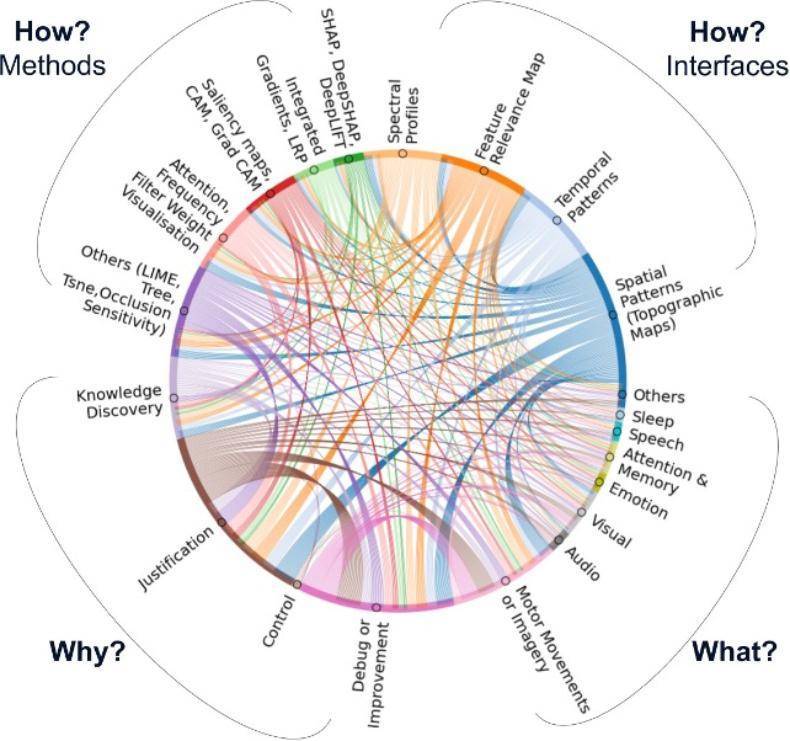
(1)全局或局部诠释:全局诠释关注模型的整体行为和规则,而局部诠释则聚焦于特定实例或决策。例如,要解释脑机接lriha6.cn/4siha6.cn/v7iha6.cn/pfiha6.cn/lviha6.cn/x9iha6.cn/bmiha6.cn/gdiha6.cn/7riha6.cn/at口驱动的机器人向右转弯的决定是否合理,解释特定实例(局部)比解释模型学习到的基本导航规则(全局)要更容易理解。因此,在解释中可以根据需要和清晰度,选择全局诠释或者局部诠释。
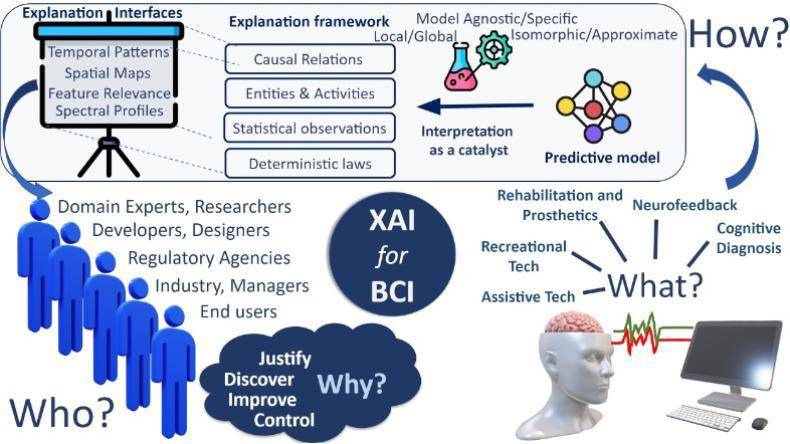

可解释人工智能的作用不仅仅是提供对模型预测的理解,还能揭示与大脑反应动态相关的深层神经机制。在诊断和康复的应用中,脑机接口的性能解释对于验证模型预测的正确性至关重要,而可解释人工智能提供了强有力的手段来实现这一点。有学者使用可解释人工智能从脑磁图(MEG)数据[7],成功识别出在伸手运动过程中处理运动参数(即加速度、速度和位置)的大脑皮层。除侵入性单神经元研究或大规模相干性研究外,可解释人工智能还提供了新的途径来研究大脑的运作机制。
目前的可解释人工智能技术也存在缺陷。有学者根据其意图将其分为两种:黑暗模式和陷阱模式[8-9]。“黑暗模式”旨在人工智能通过操纵对脑机接口的解释来伤害用户,而“陷阱模式”则是因一些知识盲区而导致人工智能产生了副作用。例如,有学者讨论了脑机接口研究中关于解码模型可解释性的一个常见误区[10]。他们强调,虽然解码模型旨在预测大脑状态以控制脑机接口,但往往存在一个隐性的假设,即这些模型的参数可以很容易地从大脑特性的角度进行人为解释。
人类普遍倾向于过度信任从有限数据集中得出的特定解释。但过度、盲目的信任存在巨大风险。因此,我们需要在设计和实施脑机接口系统时采取措施,防止利益相关者在决策中引入偏见。这意味着设计空间需要进一步发展,解释界面必须突出这一警示,提醒用户注意这些解释的潜在局限性和风险。例如,即便大脑的空间地图显示了模型预测的权衡位置,也不能保证这些大脑区域就是进行预测的最佳区域。这最终需要由利益相关者来识别和判断,以避免可能的错误。

虽然人工智能系统本身也有能力给出解释(如决策树、支持向量机等),但这些解释并不一定易于理解。例如,如果让人工智能解释“预测”(prediction)这个词,它可能会说:“参与预测的神经元由于前几层中n个神经元的一连串激活而被触发”。对于大多数人来说,这并不是一个易于理解的解释。类似的,在预测模型中人工智能喜欢用准确率、f-score、Cohen-kappa等测量方法来解释某种算法的性能,但它们并不能解释为什么此算法会达到这样的性能。
可解释人工智能的作用不仅仅是提供对模型预测的理解,还能揭示与大脑反应动态相关的深层神经机制。在诊断和康复的应用中,脑机接口的性能解释对于验证模型预测的正确性至关重要,而可解释人工智能提供了强有力的手段来实现这一点。有学者使用可解释人工智能从脑磁图(MEG)数据[7],成功识别出在伸手运动过程中处理运动参数(即加速度、速度和位置)的大脑皮层。除侵入性单神经元研究或大规模相干性研究外,可解释人工智能还提供了新的途径来研究大脑的运作机制。
目前的可解释人工智能技术也存在缺陷。有学者根据其意图将其分为两种:黑暗模式和陷阱模式[8-9]。“黑暗模式”旨在人工智能通过操纵对脑机接口的解释来伤害用户,而“陷阱模式”则是因一些知识盲区而导致人工智能产生了副作用。例如,有学者讨论了脑机接口研究中关于解码模型可解释性的一个常见误区[10]。他们强调,虽然解码模型旨在预测大脑状态以控制脑机接口,但往往存在一个隐性的假设,即这些模型的参数可以很容易地从大脑特性的角度进行人为解释。
人类普遍倾向于过度信任从有限数据集中得出的特定解释。但过度、盲目的信任存在巨大风险。因此,我们需要在设计和实施脑机接口系统时采取措施,防止利益相关者在决策中引入偏见。这意味着设计空间需要进一步发展,解释界面必须突出这一警示,提醒用户注意这些解释的潜在局限性和风险。例如,即便大脑的空间地图显示了模型预测的权衡位置,也不能保证这些大脑区域就是进行预测的最佳区域。这最终需要由利益相关者来识别和判断,以避免可能的错误。
 友情链接:
友情链接:





